
新闻中心
关注蓝耘了解更多咨询
一个被忽视的事实
Token单价趋同,但企业实际支出差距巨大
如果你正在为企业选型大模型API,大概率会先比价格。
然而我们发现了一个反直觉的事实:当前主流MaaS平台对同一模型的标准单价几乎完全一致。以DeepSeek-V3.2为例,无论你选择哪家平台,标准定价都是输入¥2.00/百万Token、输出¥3.00/百万Token。
价格拉齐了,是不是意味着选谁都一样?
答案恰恰相反。我们在服务企业客户的过程中发现,完成相同的业务目标,不同平台上的实际Token消耗量可能相差数倍——即便使用相同的模型、相同的平台、支付相同的单价。
问题出在哪里?
表面上看,Token 是一个标准化的计量单位——调用 API,模型生成 Token,按量计费,逻辑清晰。但在真实的生产环境中,“付费购买的 Token”和“真正产生业务价值的 Token”之间,存在一个常被忽视的损耗地带。
这些损耗来自两个层面:
平台/工具层面的损耗:在某些平台的政策下,请求超时可能需要重试,导致前面生成的Token全部作废;平台不稳定导致输出截断,半成品没法用,只能重新生成;峰值时段限流排队,业务系统空等;不支持上下文缓存,每次请求都为相同的 System Prompt 重复付费。
用户使用层面的损耗:提示词设计不当,模型需要多轮对话才能理解需求;上下文组织低效,携带大量无关信息;缺乏结构化输出约束,生成内容需要人工后处理或重新生成;没有针对场景优化参数,导致输出质量不稳定。
这就引出了一个被行业长期忽视的问题:我们是否一直在用错误的指标来评估 AI 推理成本?
Token单价衡量的是“买入价”。但企业真正该关心的,是“每一块钱的 Token 支出,最终产出了多少业务价值”。
重新定义成本指标:有效Token产出率
基于上述观察,我们提出一个新的评估框架——有效Token产出率(Effective Token Output Rate)。
定义:有效Token产出率=产生有效业务结果的Token数/实际消耗(含重试、浪费和冗余)的总Token数
这里的“有效”意味着:
- 请求成功完成,输出结果完整可用
- 未因超时、错误或输出截断导致重试或浪费
- 提示词设计合理,一次请求即可达成业务目标
- 上下文精简高效,不携带无关信息
有效Token产出率越高,意味着你花出去的每一个Token都在“干活”;越低,说明有大量Token消耗在了无效的重试、等待和浪费上。
影响有效Token产出率的系统性因素
我们将影响因素分为供给侧(平台/工具能力)和需求侧(用户使用方式)两个维度。
供给侧:平台与工具的五个关键维度
这些因素由服务提供方决定,用户无法直接控制,但会直接影响 Token 的实际消耗效率。
维度一
请求成功率——最直接的成本黑洞
这是唯一一个直接增加Token支出的变量。
当一次API请求失败或超时,已经消耗的Token不会退还。你必须重新发起请求,为同一个任务再付一次钱。如果平台可靠性为95%,意味着平均每20次请求就有1次失败——你的有效Token产出率直接打了95折。
更隐蔽的情况是输出截断:例如,模型已生成了800个Token,但因连接问题中断——你已支付的输出Token费用中,可能包含这部分已生成但尚未完整交付的内容。不同平台对异常中断内容的计费规则差异明显:部分平台会对异常中断、未完整交付的已生成内容全额计费;目前,蓝耘针对用户主动终止请求场景,不收取未完成输出的Token费用,进一步减少无效消耗。
在大规模调用场景下(月消耗千万级Token),5%的失败率可能意味着每月数千元的纯浪费。
维度二
上下文缓存与重复计算——容易被忽视的系统性浪费
这是我们认为最被低估的成本维度。
企业在实际使用大模型API时,大量请求的System Prompt和上下文前缀是完全相同的。例如,一个客服系统每次调用都会携带相同的系统角色描述和知识库内容,可能占到每次请求输入Token的60%-80%。
如果平台支持上下文缓存(Context Caching),这部分重复输入不需要反复计算和计费——阿里云百炼一些模型的缓存命中价格仅为标准价的10%。这意味着对于重复前缀占比高的场景,仅缓存这一项就可以大大降低成本。
而对于不支持缓存的平台,你每一次请求都在为相同的上下文重复付费。当月调用量达到百万次级别,这些重复Token的累计支出是一笔不容小觑的隐形成本。
维度三
输出完整性——最大输出长度的隐形天花板
不同平台对同一模型的最大输出长度(Max Output Tokens)支持不同。
当你的任务需要生成一篇长文、一份完整的数据分析报告、或一段较长的代码时,如果平台的最大输出限制低于任务需求,输出会被强制截断。你不得不将任务拆成多次请求,每次都要重新注入上下文——重复的上下文输入就是额外的Token消耗。
以 DeepSeek-V3.2为例,部分平台最大输出支持128K Token,而部分平台可能只支持32K Token,相差四倍。在需要长输出的场景下,一次请求完成 vs 拆成多次请求完成,会产生明显的Token消耗差距。
维度四
吞吐量与延迟——不直接影响单价,但决定业务产能
需要澄清一个常见误解:在按Token计价的模型下,吞吐量快慢本身并不改变你为同等数量Token支付的价格。不管平台每秒生成100个Token还是40个Token,1百万Token的价格都是¥3.00。
但吞吐量和延迟对企业的间接成本影响是实实在在的:
- 时间窗口约束:一个内容生产团队需要在每天早上9点前完成5000篇产品描述的AI生成。吞吐量低意味着同样的任务量需要更长的运行时间,可能需要提前到凌晨启动批处理作业,或者部署更多的并行任务。
- 用户体验与流失:在C端场景中,首Token延迟1秒和7秒的体验差距是质变级的。延迟过长导致的用户流失,是一种难以量化但非常真实的成本。
维度五
稳定性——决定你的规划必须留多少冗余
波动系数不直接让你多花Token的钱,但它决定了你必须按最差情况做资源规划。
如果某平台吞吐量在31-116 tokens/s之间波动(波动系数3.7x),你的业务系统只能按31 tokens/s来设计容量上限——因为你无法承受低谷期的服务崩溃。
这意味着:在性能好的时段,你预留的资源有大量闲置;在性能差的时段,你的服务刚好勉强撑住。你为“峰值时刻的安全感”支付了大量冗余成本。
一个波动系数2.0x的平台(最低值为峰值的50%),和一个波动系数3.7x的平台(最低值仅为峰值的27%),对企业资源规划效率的影响差距是显著的。
需求侧:用户使用方式的四个关键维度
即便平台性能完美,用户的使用方式也会极大影响 Token 的实际产出效率。这是一个常被忽视但影响巨大的成本维度。
维度六
提示词工程——决定是否“一次说清楚”
提示词设计的质量直接决定了模型理解需求的效率。
低效场景:提示词模糊、缺乏上下文、没有明确约束,导致模型需要多轮对话才能理解真实需求。一个原本可以用1次请求(输入500 Token + 输出800 Token)完成的任务,因为提示词不清晰,变成了3次请求(每次输入500 Token),总计消耗输入1500 Token + 输出800 Token,输入成本直接翻了3倍。
高效实践:
- 明确角色与任务边界:清晰定义模型的角色、任务目标和输出要求
- 提供充分上下文:给出必要的背景信息和示例,减少模型“猜测”的空间
- 结构化输出约束:使用 JSON Schema、Markdown 格式等约束输出结构,减少后处理成本
- Few-shot 示例:通过2-3个示例明确期望的输出风格和质量
一个精心设计的提示词模板,可以将多轮交互压缩为单次请求,大大提高Token使用效率。
维度七
上下文管理——避免“信息过载”
许多企业在调用 API 时,习惯性地将所有可能相关的信息都塞进上下文——“反正模型上下文窗口很大,多给点信息总没坏处”。
这是一个代价高昂的误区。
- 无关信息的成本:如果你的上下文中有40%的内容对当前任务无关,你就在为这40%的 Token 白白付费。当单次请求输入10K Token,其中4K Token 是无关信息时,你每次请求都在浪费¥0.008(按¥2.00/百万 Token 计算)。月调用10万次,累计浪费¥800。
- 信息过载的质量损失:过多的无关信息会干扰模型的注意力机制,降低输出质量。质量下降导致需要重新生成,又是一轮 Token 浪费。
高效实践:
- 上下文裁剪:根据任务类型动态选择相关上下文,而非全量注入
- 分层上下文策略:将通用知识放在 System Prompt(可缓存),将任务特定信息放在 User Prompt
- 定期审计上下文模板:检查哪些信息真正被使用,哪些是“僵尸内容”
维度八
参数调优——在质量与成本间找到平衡点
Temperature、Top-P、Max Tokens 等参数设置,直接影响输出的质量和长度。
常见低效场景:
- Temperature 过高:输出随机性大,质量不稳定,需要多次重试才能得到满意结果
- Max Tokens 设置过大:模型倾向于生成更长的输出,即便任务不需要。如果你的任务平均只需要500 Token 输出,但 Max Tokens 设置为2000,模型可能生成1200 Token 的冗长回答——多出的700 Token 是纯浪费
- 缺乏 Stop Sequences:没有设置合理的停止标记,模型可能在完成任务后继续生成无关内容
高效实践:
- 针对场景调优 Temperature:事实性任务(摘要、翻译)用低 Temperature(0.1-0.3),创意性任务(文案、头脑风暴)用中等 Temperature(0.7-0.9)
- 根据实际需求设置 Max Tokens:分析历史输出长度分布,设置合理的上限(建议在 P95值基础上增加20%缓冲)
- 使用 Stop Sequences:在任务完成标志处停止生成,避免无意义的续写
维度九
工具与工作流设计——系统性降低 Token 消耗
在应用层面,通过合理的架构设计和工具选择,可以系统性地提升 Token 效率。
高效实践:
- 本地缓存与去重:在应用层缓存常见问题的回答,避免重复调用 API
- 流式输出与早停:使用 Streaming 模式,在检测到输出质量问题时提前中止,避免生成完整的无效输出
- 分级处理策略:简单任务用小模型(如 GPT-3.5、Qwen-Turbo),复杂任务才用大模型(如 GPT-4、DeepSeek-V3),根据任务难度匹配模型能力
- 批处理优化:将多个小任务合并为一次请求,减少重复的 System Prompt 开销
行业数据验证:供给侧差异的真实影响
理论需要数据支撑。我们引用AI Ping(aiping.cn)的公开持续监测数据来验证上述框架。
AI Ping是由清华系团队搭建的大模型API第三方评测平台,对各主流MaaS平台进行7×24小时持续监测,数据公开可查。以下为2026年3月DeepSeek-V3.2模型的部分监测结果(各平台标准输出单价均为¥3.00/百万Token):
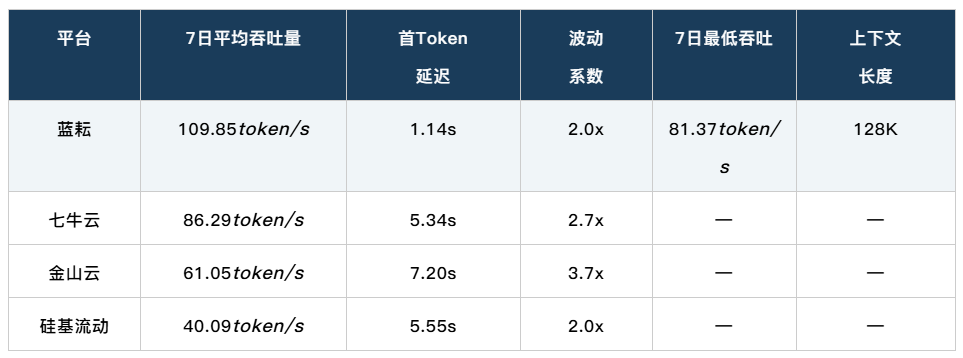
数据来源:AI Ping(aiping.cn),2026年3月持续监测,DeepSeek-V3.2模型
用我们提出的框架来看这组数据:
可靠性维度:100%可靠性意味着零重试浪费。每一个付费 Token 都在产出有效结果。而可靠性每下降5个百分点,就有5%的 Token 支出是在“为失败买单”。
效率维度:蓝耘延迟1.14秒 vs 其他平台延迟5-7秒,在实时交互场景中,同一时间窗口内的效率差距达到4-6倍。
稳定性维度:波动系数2.0x vs 3.7x,意味着资源规划效率的显著差异。低波动平台可以按更接近峰值的水平规划容量,资源利用率更高。
这些差异说明:即便 Token 单价完全相同,供给侧的能力差异也会导致企业实际成本相差数倍。
一个完整的成本优化框架
基于上述分析,我们提出企业 AI 成本优化的系统性框架:
第一步:评估供给侧能力
在选型阶段,不要只看 Token 单价,而要综合评估:
- 可靠性:7日可用率、平均故障恢复时间
- 缓存支持:是否支持上下文缓存、缓存命中价格
- 输出能力:最大输出长度、是否支持流式输出
- 性能表现:吞吐量、延迟、波动系数
- 合规与安全:等保认证、数据隔离、审计能力
建议:使用第三方评测平台(如 AI Ping)的持续监测数据,而非仅依赖服务商的宣传材料。
第二步:优化需求侧使用方式
在使用阶段,系统性提升 Token 效率:
- 建立提示词库:针对高频场景沉淀优化后的提示词模板
- 实施上下文管理:定期审计和裁剪上下文,移除无效信息
- 参数调优:根据任务类型和历史数据,优化 Temperature、Max Tokens 等参数
- 工具与流程:引入缓存、批处理、分级处理等机制
建议:建立 Token 消耗监控体系,追踪每个场景的 Token 效率指标,持续优化。
第三步:建立成本归因机制
将 Token 消耗分解为:
- 有效 Token:产生业务价值的部分
- 供给侧损耗:重试、截断、等待导致的浪费
- 需求侧损耗:提示词低效、上下文冗余、参数不当导致的浪费
通过归因分析,识别成本优化的优先级和潜力空间。
Token 单价之后,下一个问题是什么
有效 Token 产出率只是冰山一角。
它揭示的是一个更大的趋势:当 Token 单价趋同,行业竞争的焦点正在从“谁的 Token 更便宜”转向“谁能让每个 Token 产生更大的价值”。这不再是一个价格问题,而是一个效率问题——一个关于 Token 如何被生产、调度、消费的系统性问题。
当我们开始用“生产效率”而非“采购价格”的视角来看待 Token,一个更大的图景浮现出来:AI 产业正在进入以 Token 为核心生产要素的新阶段。Token 不再只是 API 的计费单位,而是整个 AI 生产体系的基本度量——就像电力之于工业体系,不只是一个价格数字,而是衡量整个生产效率的核心变量。
围绕 Token 的生产、调度与消费,一个新的产业范式正在形成。而在这个范式中,供给侧的基础设施能力和需求侧的使用效率,将共同决定企业的 AI 成本竞争力。
附
不同场景的优化策略建议
我们并不认为存在“万能”的优化方案。基于有效 Token 产出率框架的不同维度,不同场景的优化重点不同:
实时交互场景(客服、对话):
- 供给侧重点:可靠性、延迟、吞吐量
- 需求侧重点:提示词优化、上下文缓存、流式输出
- 平台选择建议:优先选择高可靠性、低延迟的平台(如蓝耘高可靠性、Deepseek-V3.2等主流模型延迟仅1s左右)
批量处理场景(内容生成、数据分析):
- 供给侧重点:上下文缓存、最大输出长度、吞吐量稳定
- 需求侧重点:批处理优化、参数调优、分级处理
- 平台选择建议:优先选择支持缓存、长输出的平台(如阿里云百炼部分模型最低缓存命中价仅10%)
探索与研发场景(模型选型、原型验证):
- 供给侧重点:模型覆盖度、灵活性
- 需求侧重点:快速迭代、A/B 测试
- 平台选择建议:优先选择模型丰富的平台(如硅基流动上百个模型)
合规敏感场景(金融、医疗、政务):
- 供给侧重点:等保认证、数据隔离、审计能力
- 需求侧重点:上下文安全管理、输出合规检查
- 平台选择建议:优先选择高合规认证的平台(如阿里云百炼等保三级)
选择的关键不在于“谁最好”,而在于你的核心场景对有效 Token 产出率的哪个维度最敏感——是可靠性、缓存复用、延迟,还是模型覆盖度;是供给侧的基础设施能力,还是需求侧的使用优化空间。
本文由蓝耘技术团队撰写。文中引用的第三方监测数据来自AI Ping(aiping.cn),蓝耘与AI Ping无商业关联。
如需了解蓝耘MaaS API的详细技术参数和企业方案,请访问 www.lanyun.net。






